ИИ канал
Канал про оценку ИИ-моделей - стоимость использования моделей (cost-per-request), качество их ответов на пользовательские запросы, комплексное сравнение ИИ-моделей по критерию цена-качество.
ИИ-модель Mistral-Nemo
Mistral-nemo — модель, выпущенная в июле 2024 года с 12 млрд. параметров и контекстом в 128k токенов — наиболее дешевая модель начала 2026 года из платных и доступных по API, разработанная французским стартапом MistralAI в сотрудничестве с NVIDIA.В марте 2026 года mistral-nemo - самая дешевая модель по критерию cost-per-request.

I. Рейтинг mistralai/mistral-nemo по категориям
1. Decide — 8 из 10. 📊
✅ Сильные стороны: высокая корректность и прозрачность критериев, хорошая полнота ключевых аспектов решения, четкое структурирование и форматирование, профессиональный и безопасный тон, комплексный учет рисков и неопределенностей.
⚠️ Слабости: способен переоценивать одни факторы за счет других, ограниченный разбор альтернатив, неполное отображение временных рамок.
🔥 Тип риска: стратегические ошибки и переоценка факторов риска при принятии решения.
Вывод: рекомендуется использовать в задачах принятия решений при достаточной валидации.2. Chat — 7 из 10. 📊
✅ Сильные стороны: эмпатия, вежливость, поддержка фасилитационной роли, ясность отдельных реплик.
⚠️ Слабости: низкая полнота диалога (требовалось 30 реплик — дан фрагмент), нарушение формата ролей, уход в обсуждение решений вместо фасилитации, неполное вовлечение пользователя, нарушения структуры потока.
🔥 Тип риска: ухудшение качества коммуникации и недопонимание в диалогах.
Вывод: ограниченная применимость, требуется доработка для полноценных фасилитационных сценариев.3. Create — 7 из 10. 📊
✅ Сильные стороны: высокая релевантность, охват запрошенных элементов, хорошая структура и ясность, единый стиль.
⚠️ Слабости: спорные обобщения без оговорок, языковые ошибки, шаблонность контента, недостаточная детализация ключевых артефактов, слабое обозначение неопределенностей.
🔥 Тип риска: генерация контента, требующего дополнительной экспертизы и доработки.
Вывод: подходит как черновой пакет для запуска с обязательной доработкой.4. Fix — 7 из 10. 📊
✅ Сильные стороны: корректное соответствие исходным данным, логичная структура, покрытие большинства проблем, профессиональный тон.
⚠️ Слабости: поверхностная диагностика и анализ первопричин, упрощенные рекомендации без учета всех факторов, недостаточная работа с неопределенностями, слабая верификация.
🔥 Тип риска: сохранение дефектов и потенциальные регрессии из-за неполного исправления.
Вывод: подходит для типовых исправлений с контролем и дополнениями.5. Explore — 6 из 10. 📊
✅ Сильные стороны: охват базовых гипотез, логичная структура, нейтральный тон, заданы направления для дальнейших исследований.
⚠️ Слабости: ограниченная глубина и оригинальность идей, частичное перекрытие кластеров, слабая работа с неопределенностями и компромисами, англоязычные вставки без контекста.
🔥 Тип риска: упущение перспективных направлений и генерация упрощенных идей.
Вывод: средняя надежность, полезно для базового расширения пространства гипотез.6. Learn — 6 из 10. 📊
✅ Сильные стороны: выдержан образовательный формат, безопасный и академический тон, сохранен фокус на учебной теме.
⚠️ Слабости: возможны существенные фактические ошибки и трансляция заблуждений, слабое согласование терминов, отсутствие иллюстративных примеров, недостаточная работа с потенциальными заблуждениями и логикой разъяснений.
🔥 Тип риска: формирование и закрепление ошибочной ментальной модели.
Вывод: ограниченная применимость для обучения; требует усиления корректности и педагогики.7. Do — 5 из 10. 📊
✅ Сильные стороны: логичная структура и группировка информации, деловой тон.
⚠️ Слабости: критические фактические ошибки в работе с данными, нарушение требований и допусков, неполнота обработки задач, игнорирование крайних случаев, недостаточная работа с неопределенностями, неверные предпосылки.
🔥 Тип риска: недостоверное выполнения задачи и получение неверных результатов.
Вывод: низкая надежность, использование в production опасно.8. Optimize — 4 из 10. 📊
✅ Сильные стороны: читаемая структура, корректный тон.
⚠️ Слабости: систематические логические ошибки и необоснованные расчеты, отсутствие реальной оптимизации, слабая увязка с входными данными, отсутствие анализа компромиссов, не признаны неопределенности, нет количественного анализа узких мест.
🔥 Тип риска: иллюзия улучшений без реального эффекта, стратегические ошибки оптимизации.
Вывод: существенно ограниченная применимость.9. Automate — 2 из 10. 📊
✅ Сильные стороны: формальное наличие запрошенных разделов, деловой тон.
⚠️ Слабости: критические ошибки в данных и ограничениях, отсутствие рандомизации, методологические ошибки, неподходящие параметры для конкретных процессов, неполное выполнение требований формата, полное игнорирование неопределенностей и предположений, слабая интеграционная пригодность, отсутствие обработки ошибок, минимальная переиспользуемость.
🔥 Тип риска: операционные сбои и некорректное использование планов автоматизации, скрытые ошибки и поломки систем.
Вывод: категорически не подходит для автоматизированного применения.
II. Сравнительный анализ
⚠️ Повторяющиеся слабости у модели:
- Недостаточная работа с неопределенностью и неполное обозначение условий применимости (Learn, Explore, Do, Optimize, Automate).
- Ошибки в Correctness при достаточно высокой Relevance (Do, Optimize, Automate).
- Часто проваливается полнота (Completeness) — незакрытые части задач и форматов (Chat, Do, Explore, Create).
- Instruction Following формально соблюдается, но сопровождается критическими содержательными ошибками (Do, Automate).🎯🔀✔️ Расхождение relevance vs correctness:
Высокая релевантность часто сопровождается ошибками в корректности или упрощениями (Decide — хорошее исключение). Особенно выражено в Automate, Do и Optimize, где заявленная тема и формат поддерживаются, но фактическое содержание не соответствует.🚨 Опасные профили:
- Automate — критический провал с correctness (1) и общей оценке по категории (2), опасность в реальной автоматизации высокая.
- Do и Optimize — низкие correctness (2 и 2) при относительно средних overall, риск получения неверных результатов велик.
- Learn с пониженной correctness (6) и критическими педагогическими ошибками может вызвать закрепление неправильных знаний.🕳️ Структурные пробелы:
- Задачи, требующие сложного рассуждения и учета неопределенностей (Learn, Explore, Optimize, Automate), показали наибольшие пробелы.
- Задачи генеративного и структурированного создания контента (Create, Fix, Decide) — сильнее.
- Диалоговые и операционные задачи имеют средние и низкие оценки соответственно, что говорит о неустойчивости модели в интерактивности и практическом выполнении.🌊 Нестабильность уверенности:
- Значительная дисперсия по correctness и completeness между категориями — от 1 (Automate) до 8–9 (Decide) указывает на нестабильность качественных показателей и потенциал для систематического падения при комплексных заданиях.
III. Общий вывод
Категории для применения в сложных задачах (уверенный силы):
- Decide (8) — подходит для практического применения при дополнительной валидации.
- Fix (7), Create (7) — надежные при использовании с контролем качества.Категории для задач средней сложности:
- Chat (7) — возможно использовать, но с риском формального и неполного диалога.
- Learn (6), Explore (6) — скорее обучающие и исследовательские, требуют усиления корректности и полноты.Категории ограниченной применимости:
- Do (5), Optimize (4) — можно применять с существенными поправками и тщательным контролем. Риски ошибок значительны.Категории, где модель использовать нельзя:
- Automate (2) — текущее состояние непригодно для применения, опасность операционных сбоев критична.Рекомендации по улучшению:
- Внедрение механизмов автоматической валидации correctness, комплексной проверки полноты и обработки неопределенностей (особенно в Do, Optimize, Automate).
- Усиление педагогической составляющей и примеров в Learn для повышения надежности в образовательных задачах.
- Контроль и проверка полноты диалогов и форматов в Chat.Категории для production:
- Наиболее надежно применять в Decide, Fix и Create с дополнительным внешним контролем. Остальные категории требуют доработки и валидации перед внедрением в продуктивные сценарии.
ИИ-модель Qwen3-235b-a22b-2507
Qwen3-235b-a22b-2507 от китайской Qwen - это мультиязычная, оптимизированная для инструкций языковая модель, основанная на архитектуре Qwen3-235B, с 22B активными параметрами на каждый прямой проход. Она оптимизирована для генерации текста общего назначения, включая следование инструкциям, логическое рассуждение, математические вычисления, код и использование инструментов. Модель поддерживает контекст длиной в 262k токенов и не реализует «режим мышления» (reasoning). По состоянию на начало весны 2026 года использование qwen3-235b-a22b-2507 обойдется для пользователя почти в 4,7 раза дороже, чем mistral-nemo.
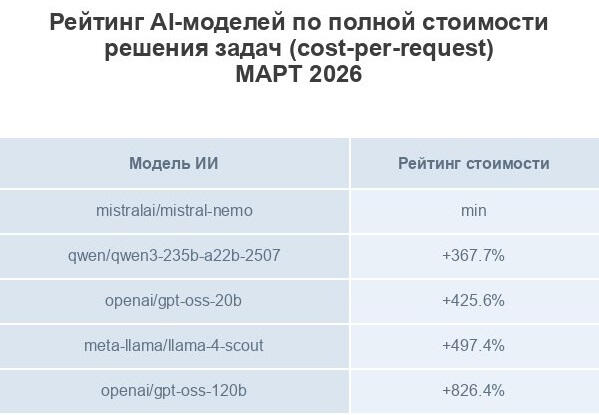
I. Рейтинг qwen3-235b-2507 по категориям
1. Explore — 9 из 10. 📊
✅ Сильные стороны: высокая релевантность, разнообразие гипотез, логичная структура и хорошее отражение неопределенности.
⚠️ Слабости: отдельные спорные термины, частично обобщенные формулировки, некоторые моменты требуют более строгой проверки фактов.
🔥 Тип риска: упущение перспективных направлений при поверхностной детализации некоторых гипотез.
Вывод: высокая надежность, подходит для исследовательских задач и генерации глубокой аналитики.2. Chat — 8 из 10. 📊
✅ Сильные стороны: адекватная реакция медиатора, уважительный тон, хорошая вовлеченность и работа с неопределенностью.
⚠️ Слабости: несоответствие формальным ограничениям (число реплик, запрет решений), частичный уход в организацию процесса, частичная неполнота.
🔥 Тип риска: снижение качества фасилитации из-за выхода за рамки роли медиатора.
Вывод: средняя надежность, подходит для поддерживающей коммуникации при контроле формата.3. Create — 8 из 10. 📊
✅ Сильные стороны: полнота структуры, соответствие запросу, ясность нарратива, полезность для практического внедрения.
⚠️ Слабости: арифметические и фактические ошибочные моменты в данных, отсутствие проработки неопределенностей, шаблонность и недостаток оригинальности.
🔥 Тип риска: невыполнение коммерческих и юридических требований, риск неправильных ожиданий.
Вывод: средняя надежность, применимо с доработкой и валидацией.4. Decide — 8 из 10. 📊
✅ Сильные стороны: доменно оправданные решения, ясные критерии, прозрачная структура, хорошо продуманное управление неопределенностью.
⚠️ Слабости: неполное рассмотрение альтернатив и дополнительных рисков, неявные ограничения и условности, использование эмодзи, уменьшающих строгость.
🔥 Тип риска: стратегическая ошибка из-за неполного учета всех опасных альтернатив.
Вывод: средняя надежность, подходит для поддержки доменного принятия решений с экспертной доработкой.5. Fix — 8 из 10. 📊
✅ Сильные стороны: обоснованная диагностика и предложение исправлений, ясная структура, наличие проверочных процедур.
⚠️ Слабости: спорные причины по некоторым дефектам, недостаточная проработка контроля и планов валидации, частичная неопределенность по недостающим данным.
🔥 Тип риска: сохранение дефекта или снижение эффективности исправлений.
Вывод: средняя надежность, подходит для техничных задач с привлечением специалиста.6. Learn — 8 из 10. 📊
✅ Сильные стороны: корректность терминов и алгоритмов, хорошая структура, понятное изложение, аккуратное обращение с неопределенностью.
⚠️ Слабости: почти отсутствуют обучающие примеры и аналогии, частично бинарное обозначение неопределенности, некоторые термины вводят двусмысленность.
🔥 Тип риска: формирование неполного или однобокого понимания.
Вывод: средняя надежность, эффективна для обучающих материалов при дополнении пояснениями.7. Do — 6 из 10. 📊
✅ Сильные стороны: структурированность, релевантность задачи, удобная для отчетности организация информации.
⚠️ Слабости: критические ошибки в подборе и учете данных, нарушение правил формирования артефактов, противоречия в выводах, неверные допущения.
🔥 Тип риска: невозможность правильно выполнить задачу из-за неверных подсчетов и пропусков.
Вывод: ограниченная применимость, требует обязательной проверки и доработки перед использованием.8. Optimize — 5 из 10. 📊
✅ Сильные стороны: выявление узких мест, анализ экстремумов, попытка балансировать компромиссы.
⚠️ Слабости: критические методологические ошибки в расчетах и предположениях, отсутствие верифицируемого итога, игнорирование операционных ограничений и особенностей.
🔥 Тип риска: получение операционно неосуществимой оптимизации с ложным улучшением.
Вывод: ограниченная применимость, требует экспертного вмешательства и доработки.9. Automate — 3 из 10. 📊
✅ Сильные стороны: частичное соблюдение структуры, базовое упоминание контроля качества и повторов.
⚠️ Слабости: критические нарушения лимитов, неполные данные, отсутствие машиночитаемого формата, неучтенные ограничения и необработанные неопределенности.
🔥 Тип риска: поломка автоматизированного пайплайна, неисполнение и ошибки при внедрении.
Вывод: рискованная категория, неприменима в промышленных условиях.
II. Сравнительный анализ
⚠️ Повторяющиеся слабости:
- Несоответствие строгим требованиям формата и инструкциям (Chat, Do, Automate);
- Поверхностное и небрежное обращение с неопределенностью (Create, Optimize, Automate, Do);
- Местами спорные или неточные фактические данные (Create, Fix, Learn, Explore);
- Отсутствие глубокой проверки альтернатив и сценариев (Decide, Optimize).⛔ Часто проваливаемые критерии:
- Correctness – критичные ошибки в практических Do, Optimize, Automate;
- Instruction Following / Format Adherence – многочисленные нарушения в Chat, Do, Optimize, Automate;
- Uncertainty Handling – слабая проработка во многих категориях с критичными вычислениями;
- Completeness – пробелы в данных и детализации в Do, Optimize, Automate.🎯🔀✔️ Расхождение relevance vs correctness:
- Большинство категорий показывают высокий relevance с умеренным correctness, что означает, что модель понимает запросы, но реализует их со значительными ошибками в деталях (особенно практические категории). Explore и Learn – пример сбалансированности. Automate сильно страдает от нехватки правильности при средней релевантности.🚨 Опасные профили:
- Automate (Correctness - 3, общая оценка - 3) – высокий риск полного сбоя пайплайна;
- Optimize (Correctness - 3, общая оценка - 5) – риск операционной неосуществимости и ложной экономии;
- Do (Correctness - 4, общая оценка - 6) – риск ошибочного результата при выполнении.
III. Общий вывод
Применимость в категории для сложных задач:
- Explore - нет рисков серьезных ошибок и низкой надежности.Категории для задач средней сложности (допускают использование с проверкой):
- Chat, Create, Learn, Fix, Decide - устойчивое качество, но есть пробелы в корректности или полноте.Категории ограниченной применимости:
- Do, Optimize - потребуют доработки и валидации данных экспертам.Категории, где модель использовать нельзя:
- Automate - критические ошибки и отсутствие полного результата.Где автоматическая валидация улучшит результат:
- Во всех категориях с низким correctness и нарушениями формата, особенно Do, Optimize, Automate.
- В Learn и Create валидация поможет устранить арифметические и фактические несостыковки.Какие категории подходят для production:
- Explore — исследовательские сценарии и генерация идей;
- Learn — образовательные материалы при условии усиления примерами;
- Chat — коммуникация и фасилитация при строгом контроле формата;
- Fix — технические исправления с экспертами.Общий профиль модели:
Высокая релевантность и структурированность в исследовательских, когнитивных и просветительских задачах при достаточно устойчивом корректном изложении. Имеются слабости в строгом следовании инструкциям и критичная корректность в прикладных практических сценариях, особенно в автоматизации и сложных вычислительных задачах. Неопределенность и допущения часто отражаются поверхностно или небрежно, что создает риски ошибочной интерпретации и низкой надежности в областях с жесткими ограничениями.
ИИ-модель GPT-oss-20b
Gpt-oss-20b от OpenAI - это модель с открытыми весами, 21 миллиардом параметров и контекстным окном в 128k токенов, выпущенная OpenAI под лицензией Apache 2.0. Она использует архитектуру MoE с 3,6 миллиардами активных параметров на каждый инференс. Затраты на ее использование в начале 2026 года будут в среднем в 2,5 раза выше, чем у mistral-nemo.

I. Рейтинг openai/gpt-oss-20b по категориям
1. Chat — 6 из 10. 📊
✅ Сильные стороны: сохранение релевантности темы, вежливый и эмпатийный тон, понятная базовая структура диалога, хорошее обращение с неопределенностью.
⚠️ Слабости: ошибки в формальных требованиях, нарушение запрета на предложения решений, странные выдуманные термины, формальные и стилистические шероховатости, частичные логические сдвиги определенной роли.
🔥 Риск: снижение доверия к диалогу, ложная уверенность в фасилитации, нарушение формата.
Вывод: возможна ограниченная применимость для разговорной поддержки, но с контролем формата.2. Decide — 6 из 10. 📊
✅ Сильные стороны: корректно структурированные предложения, основные критерии выбора представлены, формат соблюден.
⚠️ Слабости: ошибки в терминах, некорректные расчеты, нечеткие пороги тестов, недостаток прозрачности выбора, частичная неполнота покрытия альтернатив и рисков, небезопасная категоричность в рекомендациях лечения.
🔥 Риск: принятие неверного решения, опасность неправильного руководства.
Вывод: применимость существенно ограничена — требует валидации и экспертной проверки.3. Do — 6 из 10. 📊
✅ Сильные стороны: логичное выполнение шагов отчета, четкая структура, фильтрация и подсчеты, деловой тон.
⚠️ Слабости: ошибки в данных и датах, важные отклонения не зафиксированы, неполное покрытие операций и крайних случаев, отсутствие сомнений по спорным данным, слабо проработано действие при ошибках.
🔥 Риск: неверное исполнение процедур, скрытые ошибки в отчетах, снижение доверия к результатам.
Вывод: возможно ограниченное использование с дополнительной валидацией.4. Explore — 6 из 10. 📊
✅ Сильные стороны: широкий набор гипотез с охватом различных факторов, формальный формат исследования соблюден, аналитический стиль.
⚠️ Слабости: множество бессмысленных терминов и языковых ошибок, частичная неполнота раскрытия логики и различений гипотез, сомнительность формулировок предсказаний, плохая ясность структуры по кластерам.
🔥 Риск: генерация псевдо-идей, затруднение использования в исследовательской работе.
Вывод: ограниченная применимость — требует серьезного экспертного контроля.5. Learn — 6 из 10. 📊
✅ Сильные стороны: верные ключевые расчеты и логика классификации, аккуратное разделение концепций, нейтральный и безопасный тон.
⚠️ Слабости: терминологические ошибки и путаница, нет педагогических примеров и аналогий, неоднозначности и слабая работа с возможными заблуждениями, некоторые выводы поданы слишком уверенно.
🔥 Риск: закрепление неправильных понятий, неполное образовательное понимание темы.
Вывод: подходит исключительно для поддержки в образовательном процессе, но требует редакторского контроля и адаптации.6. Create — 5 из 10. 📊
✅ Сильные стороны: формальное соблюдение структуры, попытка включить уникальные элементы, маркетинговый стиль.
⚠️ Слабости: серьезные языковые и фактологические ошибки, отсутствие учета локального контекста, манипулятивные заявления, практически полное отсутствие обозначения неопределенности, высокая вероятность введения в заблуждение.
🔥 Риск: генерация нерелевантного и потенциально вводящего в заблуждение контента, неправильное восприятие пользователем.
Вывод: пригоден только как заготовка с большой редакторской доработкой.7. Fix — 5 из 10. 📊
✅ Сильные стороны: правильная диагностика ключевых проблем, структурированная инструкция, наличие контроля дефектов и измерений, деловой тон.
⚠️ Слабости: технические ошибки и несоответствия параметров, допуски без обоснования, отсутствие детального рассмотрения некоторых критичных параметров, слабое управление неопределенностью, методологические неточности в анализе причин, ограниченная верификация.
🔥 Риск: сохранение дефектов, риски регрессий, возможные некорректные поправки.
Вывод: низкая применимость — требует экспертной проверки и доработки.8. Optimize — 5 из 10. 📊
✅ Сильные стороны: логичная структура, идея динамической регулировки выпуска, грамотный деловой тон.
⚠️ Слабости: серьезные ошибки в исходных данных, недостоверные расчеты, отсутствие детализации, необоснованная уверенность, отсутствие анализа компромиссов, отсутствие проверки чувствительности, нечеткая диагностика узких мест.
🔥 Риск: неверные решения по оптимизации, фиктивный эффект улучшений, трудности внедрения.
Вывод: только для предварительного обсуждения задачи.9. Automate — 3 из 10. 📊
✅ Сильные стороны: попытки структурирования и создания шаблонов, деловой стиль, релевантность тематике.
⚠️ Слабости: масштабные нарушения ограничений, неполные и непоследовательные артефакты, неподходящий формат для импорта, отсутствие учета реальных условий и обработки ошибок, отсутствие параметризации и гибкости, игнорирование неопределенностей.
🔥 Риск: поломка автоматизированных процессов, генерация невалидных конфигураций, невозможность полноценной интеграции без ручной доработки.
Вывод: использовать нельзя.
II. Сравнительный анализ
⚠️ Частые слабости: низкий correctness (в 7 из 9 категорий - ниже 6, в 2 — ниже 4), нарушение instructions и format (особенно Chat, Automate, Do, Fix), высокий уровень неопределенности без достаточного их признания (исключительно плохая оценка uncertainty в Create и Automate).⛔ Повторяющиеся проблемы с ясностью терминологии и фактологическими ошибками (Decide, Learn, Automate, Fix).🎯🔀✔️ Расхождение relevance vs correctness встречается, например, в Decide и Automate — высокая релевантность при низкой correctness создают риск ложной уверенности.🚨 Опасные профили: Automate (correctness - 2, общая оценка - 3) и Create (uncertainty handling - 2) — создают значительный системный риск.🕳️ Структурные пробелы: слабая работа с неопределенностями и слабое следование инструкциям, особенно нарушения формата и требований к ограничениям.
III. Общий вывод
Сложные задачи (требующие точности и безопасности): не применимо.Задачи средней сложности: Chat, Decide, Do, Learn, Explore — ограниченная применимость, нужны дополнительные проверки и корректировки. В этих задачах модель имеет средний уровень стабильности и пригодна для пилотных проектов или внутреннего использования с контролем качества.Категории ограниченной применимости: все, кроме Automate считаются ограниченными (общая оценка по категориям от 5 до 6); ни одна категория не достигла высокого уровня надежности (более 8).Рекомендации по автоматической валидации:
- Do и Fix — нужна проверка данных и алгоритмов подсчетов;
- Automate и Optimize — обязательна валидация исходных параметров и ограничений;
- Decide и Learn — нужна верификация фактических данных и терминов.Для production подходит только Chat, если строго контролировать формат и ограничения, и при наличии дополнительной модерации.
ИИ-модель Llama 4 Scout
Meta-llama/llama-4-scout - это MoE-модель, которая при инферансе активирует 17 миллиардов параметров из общих 109 миллиардов, обладает контекстным окном в 327 680 токенов и поддерживает нативный мультимодальный (текст, код и изображение) многоязычный (12 языков) ввод-вывод. Она была выпущена под лицензией Llama 4 Community License, была в последний раз обучена на данных до августа 2024 года и запущена публично 5 апреля 2025 года.
Ее cost-per-request на начало 2026 года в среднем почти в 6 раз выше, чем у Mistral Nemo.

I. Рейтинг llama 4 scout по категориям
1. Decide — 7 из 10. 📊
✅ Сильные стороны: адекватный фокус на сценарии, логичная структура, четкая финальная рекомендация, высокий уровень релевантности.
⚠️ Слабости: недостаточная проработка альтернатив, не полностью раскрыты критерии выбора и пороги, возможность включения спорных стресс-тестов, частичная неясность формулировок.
🔥 Риск: принятие неоптимального решения из-за недостаточной полноты и прозрачности.
Вывод: пригодна для поддержки принятия решений с обязательной проверкой и валидацией.2. Explore — 7 из 10. 📊
✅ Сильные стороны: широкий охват гипотез, понятная структура, сохранение тематической релевантности, нейтральный аналитический тон.
⚠️ Слабости: недостаточная детализация механизмов, неявная связь между гипотезами, обобщенные формулировки предсказаний, неполное учет неопределенности.
🔥 Риск: генерация поверхностных направлений, упущение сложных и необычных идей.
Вывод: применима для первичного исследования и формирования направлений с дальнейшей доработкой.3. Learn — 7 из 10. 📊
✅ Сильные стороны: структура ответа соответствует запросу, нейтральный тон, признание неопределенности, общее покрытие терминологии.
⚠️ Слабости: фактические неточности в ключевых определениях, низкая педагогическая ясность, отсутствие примеров, слабая работа с распространенными заблуждениями.
🔥 Риск: формирование ошибочного понимания темы и закрепление неверных представлений.
Вывод: подходит для базового обучения с дополнительной экспертизой и детализацией.4. Create — 6 из 10. 📊
✅ Сильные стороны: релевантность контента, логичная структура, профессиональный тон.
⚠️ Слабости: поверхностность раскрытия, совсем не учтена неопределенность, шаблонность и низкая оригинальность, недостаточная детализация требуемых артефактов.
🔥 Риск: создание неприменимых или слишком общих продуктов, что снижает эффективность запуска.
Вывод: использование ограничено подготовкой набросков, требует редакторской доработки.5. Fix — 6 из 10. 📊
✅ Сильные стороны: выявление основных проблемных зон, понятная структура, профессиональный и безопасный стиль.
⚠️ Слабости: некорректное технико-технологическое соответствие, неполное покрытие контрольных операций, слабое руководство по проверке.
🔥 Риск: неполноценное устранение дефектов, возможные регрессы и риски технологических сбоев.
Вывод: может служить стартовой точкой для исправления с обязательным профессиональным контролем.6. Chat — 5 из 10. 📊
✅ Сильные стороны: поддержание темы, умеренный тон и вежливость, некоторый уровень вовлеченности.
⚠️ Слабости: критические нарушения формата, нарушение ролевых установок, смешение фасилитации с предложениями решений, недостаточная полнота диалога.
🔥 Риск: снижение качества коммуникации, недопонимание, потеря доверия к фасилитации.
Вывод использование с ограничениями, не подходит для реальных сценариев без корректировки.7. Do — 4 из 10. 📊
✅ Сильные стороны: форма ответа понятна, частичное соответствие структуре запроса.
⚠️ Слабости: критические ошибки в учете данных, пропуск ключевых фильтров, отсутствие проверки допусков и пояснений алгоритма, неправильные даты.
🔥 Риск: невозможность выполнить задачу корректно, неверные управленческие решения.
Вывод: применимость сильно ограничена, результат требует полной переработки.8. Automate — 3 из 10. 📊
✅ Сильные стороны: последовательная структура и деловой тон, присутствие шаблонов и разделов.
⚠️ Слабости: отсутствие технической корректности, игнорирование рандомизации, неполнота расписания, неоперациональные правила, слабая интеграционная пригодность.
🔥 Риск: поломка автоматизированных пайплайнов, генерация невалидных данных.
Вывод: не применима для продуктивной автоматизации в текущем виде.9. Optimize — 3 из 10. 📊
✅ Сильные стороны: формальное отражение запроса, выделение узких мест.
⚠️ Слабости: серьезные математические ошибки, отсутствие необходимых артефактов, плохое раскрытие trade-offs, отсутствие проверки ограничений.
🔥 Риск: стратегическая ошибка, принятие неэффективных решений.
Вывод: непригодна для оперативного использования.
II. Сравнительный анализ
⚠️ Повторяющиеся слабости:
— Недостаточная детализация и прозрачность критериев (Decide, Learn, Explore)
— Неадекватная работа с неопределенностью и допущениями (Create, Automate, Optimize)
— Ограниченное покрытие альтернатив и опций (Decide, Explore)
— Проблемы с корректностью ключевых данных и фильтров (Do, Fix, Automate, Optimize)
— Нарушения формата и инструкций, особенно в Chat и Do.⛔ Чаще всего проваливаются критерии:
- Correctness (низкие оценки в Do, Automate, Optimize, Chat)
- Instruction Following (низк в Chat, Automate, Do)
- Completeness (низк в Do, Automate, Optimize, Create).🎯🔀✔️ Расхождение Relevance vs Correctness:
- Систематически наблюдается высокий Relevance при средних и низких Correctness (например, Decide, Explore, Create), что создает риск уверенного, но ошибочного вывода.🚨 Опасные профили:
— Do, Automate и Optimize — низкий correctness и completeness, высокая системная неопределенность и риск получения неверных практических результатов.
— Chat — критические нарушения ролевой структуры и формальных требований.
III. Общий вывод
- Сложные задачи: не допускаются
- Задачи средней сложности (возможна поддержка с дополнениями): Decide, Explore, Learn
- Простые задачи: Create, Fix, Chat
- Категории, где модель использовать нельзя без серьезной правки: Do, Automate, OptimizeМеста для автоматической валидации:
- корректность данных и фильтров в Do;
- техническая проверка расписаний и ограничений в Automate;
- верификация математических расчётов в Optimize;
- проверка соблюдения ролей и формата в Chat.Кандидаты для production (с доработками и мониторингом):
- Decide (в части принятия решений), Explore (для идей), Learn (для базового обучения).
- Остальные требуют существенной адаптации или не подходят для ответственных сценариев.Данный анализ выявляет значимые структурные пробелы модели в обеспечении полноты, корректности и стабильности во множестве категорий, ограничивая ее применимость в приложениях с высокими требованиями к надежности и безопасности.
ИИ-модель GLM 4.5 Air
Z-ai/glm-4.5-air - это облегченный вариант китайской модели GLM-4.5, тоже использующий архитектуру MoE, но с более компактным размером параметров. GLM-4.5-Air поддерживает гибридные режимы вывода, предлагая «режим мышления» для углубленного анализа и использования инструментов, и «режим без мышления» для взаимодействия в реальном времени. Затраты на ее использование в феврале 2026 года были почти в 9 раза выше, чем у mistral-nemo.
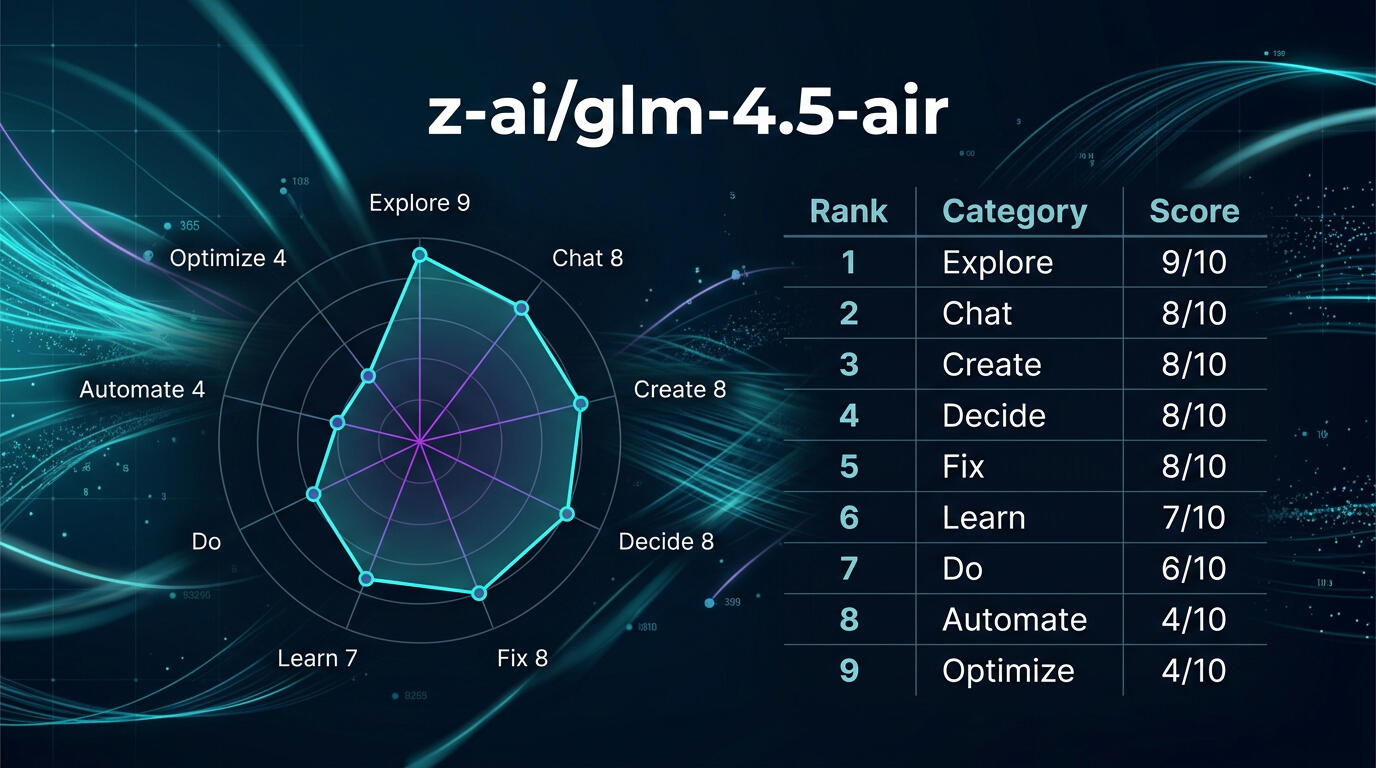
I. Рейтинг glm-4.5-air по категориям
1. Explore — 9 из 10. 📊
✅ Сильные стороны: Высокая релевантность и широкое покрытие гипотез, аккуратная структуризация идей, прозрачное выделение рисков и конфликтов, нейтральный и академичный стиль.
⚠️Слабости: Легкие упрощения и дублирование кластеров, недостаточное разграничение альтернативных механизмов, частичное неучет нюансов неопределенности внутри кластеров.
🔥 Тип риска: Упущение важных причинных каналов и формирование неокончательных ментальных моделей.
Вывод: Высокая надежность, подход для глубокого исследовательского анализа.2. Chat — 8 из 10. 📊
✅ Сильные стороны: Логичная фасилитация диалога, эмпатия и вежливость, хорошая вовлеченность, поддержка контекста.
⚠️Слабости: Несовершенство формата (смешение меток ролей), нестрогое соответствие количеству реплик, стартовые допущения роли пользователя без уточнения.
🔥 Тип риска: Недопонимание из-за путаницы ролей и легкого ухода от формата.
Вывод: Средняя надежность, применима для моделирования диалога с рекомендацией улучшить форматирование.3. Create — 8 из 10. 📊
✅ Сильные стороны: Закрытие всех запрошенных элементов, понятная структура курса и маркетинга, целостный «черновик» продукта.
⚠️Слабости: Наличие артефактов (китайские символы), спорные финансовые советы без оговорок, слабая работа с неопределенностью ниши и аудитории, шаблонность некоторых решений.
🔥 Тип риска: Потенциальный риск плохих инвестсоветов и несоответствия конкретным условиям.
Вывод: Средняя надежность, требует редакторской доработки и проверки финансовой безопасности.4. Decide — 8 из 10. 📊
✅ Сильные стороны: Обоснованный выбор варианта с прозрачными критериями и балансовой оценкой рисков, четкая структура, уместный профессиональный тон.
⚠️Слабости: Недостаточная детализация по альтернативным угрожающим диагнозам, нечеткие пороги для перегруппировки вариантов, частичные неявные допущения при отсутствии данных.
🔥 Тип риска: Возможные ошибочные решения из-за неполной картины доменной безопасности.
Вывод: Средняя надежность, подходит для поддержки решений с дополнительной валидацией.5. Fix — 8 из 10. 📊
✅ Сильные стороны: Корректная диагностика ключевых причин, логичная переконфигурация производственного процесса, подробное планирование контроля.
⚠️Слабости: Технические неточности в интерпретации параметров, недостаточная проработка вариантов и условий эскалации, пропуски по оборудованию и состоянию оснастки.
🔥 Тип риска: Сохранение дефекта из-за неполного покрытия причин и отсутствия «если/то» логики.
Вывод: Средняя надежность, полезно для инженерных поправок с оговоркой на уточнение параметров.6. Learn — 7 из 10. 📊
✅ Сильные стороны: Корректное согласование пороговых значений, прозрачное структурирование выводов, нейтральный и профессиональный стиль.
⚠️Слабости: Внутренние логические несогласованности в трактовке, отсутствие обучающих примеров и аналогий, частичная неявность гипотез и неопределенность.
🔥 Тип риска: Формирование путаницы в обучающих выводах и ограниченный педагогический эффект.
Вывод: Средняя надежность, применима для базового обучения с доработкой по обучающим материалам.7. Do — 6 из 10. 📊
✅ Сильные стороны: Основной объем данных собран и структурирован, понятный формат отчета, последовательная логика.
⚠️Слабости: Критические ошибки в подсчетах и обработке данных, нарушение правил отбора (дубликаты), неучет важных отклонений и пограничных случаев, недостаточная фиксация неопределенности.
🔥 Тип риска: Получение неправильных вычислительных выводов и ошибочная отчетность.
Вывод: Ограниченная применимость, необходима доработка и проверка перед использованием.8. Automate — 4 из 10. 📊
✅ Сильные стороны: Тематическая релевантность, представленность ключевых элементов плана, деловой технический стиль.
⚠️Слабости: Множественные нарушения ограничений и технических правил, неполнота планов, отсутствие явной рандомизации, плохо формализованное расписание, низкая гибкость и перенастраиваемость, слабое учет неопределённости.
🔥 Тип риска: Генерация невалидных планов с ошибками интеграции и низкой устойчивостью к изменениям.
Вывод: Ограниченная применимость, не готово к продакшн-автоматизации.9. Optimize — 4 из 10. 📊
✅ Сильные стороны: Идентификация узких мест и общая структурированность анализа, профессиональный тон.
⚠️Слабости: Критические ошибки в расчетах и несоблюдении жестких ограничений, неконсистентность данных, отсутствие полноценного расписания, слабая проработка компромиссов и влияния неопределенности, низкая практическая применимость.
🔥 Тип риска: Невыполнимые оптимизационные решения; иллюзия улучшения без эффекта.
Вывод: Ограниченная применимость, не готово к продакшн-применению.
II. Сравнительный анализ
⚠️ Повторяющиеся слабости:
- Проблемы с полноценной, работой с неопределенностью и допущениями встречаются в Create, Learn, Do, Automate, Optimize.
- Ошибки в корректности (Correctness) критичны для Do, Automate, Optimize, а также встречаются в Create, Fix, Learn, что отражает вызовы на прагматичных и технических задачах.
- Нарушения формата и следования инструкциям особо заметны в Chat, Automate, Do, Optimize, что снижает надежность результатов.
- Часто встречается неполное покрытие требований (Completeness) в Do, Automate, Optimize, Create.⛔ Часто проваливаемые критерии:
- Correctness ниже 5 в Do (4), Automate (2), Optimize (2), что повышает риски использования.
- Uncertainty Handling средний/низкий в большинстве категорий, особенно низкий в Automate (3) и Optimize (4).
- Instruction Following частично не выполнен в Automate (3), Optimize (3), Do (6).🎯🔀✔️ Расхождение relevance vs correctness:
- В Automate и Optimize релевантность средняя (7), но Correctness критично низкая (2), что создает опасные профили: результат релевантен, но фактически неверен и непригоден.
- В Do Relevance выше (8), но Correctness на пороге риска (4), что ставит под сомнение применение без контроля.🚨 Опасные профили:
- Автоматизация (Automate) и оптимизация (Optimize) имеют профиль с низкой Correctness и Uncertainty Handling – повышается риск нежелательных последствий в продакшн.
- Do с близким к риску Correctness и проблемами в учете данных – потенциально опасна для прямого внедрения.
- Learn и Create демонстрируют более сбалансированное качество, но требуют доработки по обучению и безопасности соответственно.
III. Общий вывод
Категории для сложных и критичных задач (глубокий анализ, исследование, принятие решений):
- Explore (высокая надёжность, 9), Decide (8). Подходят для production и принятия обоснованных решений с обязательным контролем.Категории для задач средней сложности (творческое создание, коммуникация, исправление):
- Chat (8), Create (8), Fix (8), Learn (7). Используемы с доработкой формата и экспертными дополнениями по безопасности/обучению.Категории ограниченной применимости (практические инструкции, отчеты):
- Do (6). Требует проверки и корректировки перед применением, высок риск ошибочных результатов.Категории, где модель использовать нельзя без значительной доработки и валидации:
- Automate (4), Optimize (4). Низкая техническая корректность и надежность делают недопустимым продакшн-применение.Рекомендации для улучшения
- Внедрение автоматической валидации Correctness и форматных требований для снижения ошибок в Do, Automate, Optimize.
- Улучшение работы с неопределенностью и оговорками (Uncertainty Handling) во всех категориях с прагматическим уклоном.
- Строгий контроль Instruction Following / Format Adherence для повышения стабильности мультитасковых сценариев (Chat, Automate).
- Усиление обучающих компонентов и примеров в Learn для повышения понимания и снижения рисков ложных выводов.Категории, готовые к production-сценариям с минимальной доработкой:
Explore, Decide — для сложного анализа и рекомендации.
Chat, Fix — для поддержки коммуникации и исправлений.
Create — при дополнительной редактуре по безопасности.Вывод:
Модель демонстрирует сильные стороны в генерации комплексных, тематически релевантных и структурированных текстов для исследовательских (Explore) и коммуникативных (Chat) задач, а также для решений с четкой логикой выбора (Decide) и инженерных рекомендаций (Fix). В то же время ей свойственны проблемы с технической корректностью и полнотой в прагматичных заданиях на исполнение (Do), автоматизацию (Automate) и оптимизацию (Optimize). Обработка неопределенности и следование инструкциям показывают значительную вариативность, что создает риски надежности.Таким образом, z-ai/glm-4.5-air успешно справляется с аналитическими, коммуникативными и творческими задачами, однако испытывает существенные трудности со строго исполненными и технически корректными автоматизацией и оптимизацией. Для таких задач необходима замена модели.
ИИ-модель GPT oss 120b
Openai/gpt-oss-120b - открытая MoE модель с 117 миллиардами параметров, представленная в августе 2025 года, и позиционируемая как модель для задач, требующих логического мышления, агентного подхода и общего назначения. Она активирует 5,1 миллиарда параметров за один проход и оптимизирована для работы на одном графическом процессоре H100 с нативным квантованием MXFP4. Здесь модель оценивается “как есть” - на базовых настройках провайдеров, - но нужно иметь ввиду, что модель поддерживает настраиваемую глубину логического мышления и использование нативных инструментов, включая вызов функций и генерацию структурированного выхода. Одновременно, даже “на базовых настройках” cost-per-request для gpt-oss-120b в начале 2026 года будет более чем в 9 раз выше, чем у самой дешевой Mistral Nemo.

I. Рейтинг gpt oss 120b по категориям
Chat — 9 из 10. 📊
✅ Сильные стороны: высокое соответствие тематике и форматам диалога, грамотная фасилитация, ясная структура, выдающаяся эмпатия и поддержка вовлеченности, корректный тон и безопасный стиль.
⚠️ Слабости: пониженное удержание границ формата, возможно частичное нарушение инструкций по запретам.
🔥 Тип риска: смещение цели диалога — уход в обсуждение решений вместо фасилитации, что снижает доверие и качество коммуникации.
Вывод: категория высокой надежности для задач фасилитации и поддержки диалога.Decide — 8 из 10. 📊
✅ Сильные стороны: адекватный доменный выбор, верное распознавание неопределенности и рисков, прозрачная структура и аргументация. Высокая релевантность.
⚠️ Слабости: доменные неточности и терминологические ошибки, слабая сбалансированность оценки альтернатив, присутствие нерелевантных деталей, нечеткость критериев принятия решений.
🔥 Тип риска: возможное смещение доменного выбора из-за ошибок терминологии и пропуска опасных альтернатив.
Вывод: категория устойчивого качества с областью экспертных доработок в деталях и балансировке аргументации.Explore — 8 из 10. 📊
✅ Сильные стороны: широкий спектр идей и гипотез, хорошая структурная организация, корректное обращение с неопределенностью и рисками, высокий потенциал для дальнейших исследований.
⚠️ Слабости: локальные логические и фактологические огрехи, запутанность в нумерации, частичные нарушения формата и недостаток строгости в предсказаниях.
🔥 Тип риска: генерация нерелевантных или частично ошибочных исследовательских направлений.
Вывод: категория устойчивого качества для исследовательских и аналитических задач. Возможно потребует выборочного экспертного контроля.Create — 7 из 10. 📊
✅ Сильные стороны: выполнение требований по содержанию и форматам, хорошая структурированность, полезность результата как базового шаблона.
⚠️ Слабости: противоречия внутри материалов, фактические ошибки в цифрах и ограничениях, низкий уровень маркировки рисков, рискованные маркетинговые заявления без дисклеймеров.
🔥 Тип риска: создание вводящего в заблуждение контента с потенциальными юридическими и этическими рисками.
Вывод: категория средней надежности с ограничениями по финализации и корректности.Learn — 7 из 10. 📊
✅ Сильные стороны: правильная концептуальная структура, высокая релевантность тематике источников, ясная логика и форматирование, грамотное выделение неопределенностей и рисков, хороший педагогический подход.
⚠️ Слабости: некоторые фактические ошибки в расчетах и критериях, недостаток примеров и аналогий, частичное неправильное трактование критериев из источников, завышенная уверенность в некоторых выводах.
🔥 Тип риска: формирование частично неверных ментальных моделей и заблуждений.
Вывод: категория средней надежности, требующая дополнений примерами и точной верификации фактов.Do — 6 из 10. 📊
✅ Сильные стороны: верное выделение ключевых операций и базовый подсчет, адекватность общего ответа поставленной задаче.
⚠️ Слабости: противоречия в итоговых числах, плохая прозрачность расчетов, наличие артефактов и мусорных вставок, неполное соблюдение группировки и предпосылок, слабое управление неоднозначностями.
🔥 Тип риска: получение некорректного отчета с невозможностью повторной проверки данных, снижение практической применимости.
Вывод: категория ограниченной применимости, требует экспертного вмешательства по контролю результата.Fix — 6 из 10. 📊
✅ Сильные стороны: частичное исправление несоответствий, диагностика основных проблем, формальное соблюдение формата артефактов.
⚠️ Слабости: фактические и технические ошибки, галлюцинации, неполное покрытие контроля и верификации, плохая читаемость из-за опечаток и странных вставок, отсутствие учета вариативности и альтернативных сценариев.
🔥 Тип риска: сохранение дефектов и деградация инструкций по исправлению.
Вывод: категория ограниченной применимости с риском нестабильности системы после исправления.Optimize — 6 из 10. 📊
✅ Сильные стороны: выделение ключевых узких мест, операционно реализуемые предложения, признание trade-offs.
⚠️ Слабости: некорректные исходные данные, отсутствие необходимых артефактов, слабая прозрачность сравнения "до/после", неучтенные неопределенности и допущения, лишние объекты в тексте.
🔥 Тип риска: иллюзорное улучшение без реального эффекта, снижение устойчивости решения.
Вывод: категория ограниченной применимости, требующая доработки точности и учета критичных параметров.Automate — 4 из 10. 📊
✅ Сильные стороны: наличие разделения на ключевые секции, базовые проверки целостности данных.
⚠️ Слабости: критические ошибки фактического и логического характера, частичная или отсутствующая рандомизация, неполные run-листы, сложности с интеграцией, отсутствие явных допущений и механизмов контроля ошибок, неоднозначность данных, множество артефактов и мусорных вставок.
🔥 Тип риска: потеря ресурсов и времени, поломка автоматизированных процессов, невозможность запуска в production.
Вывод: категория рискованной применимости, не готова к промышленному использованию.
II. Сравнительный анализ
⚠️ Повторяющиеся слабости:
• Частые фактические и терминологические ошибки (Correctness) в Do, Fix, Optimize, Automate и Learn.
• Проблемы с полнотой и прозрачностью расчетов или данных (Completeness, Step-by-step, Prerequisites) в Do, Fix, Optimize.
• Нарушения Instruction Following / Format Adherence, особенно при переходе от когнитивных к техническим категориям (Fix, Automate, Optimize).
• Плохая работа с неопределенностью (Uncertainty Handling) выражена в Automate, Optimize, Do, Fix.
• Артефакты, мусорные вставки и опечатки — сквозная проблема в технических задачах (Fix, Automate, Optimize, Do).🎯🔀✔️ Особенности релевантности vs correctness:
• В Decide и Explore высокая релевантность при умеренной или пониженной корректности — риски ложной уверенности по профессиональным решениям.
• В Chat релевантность и correctness обе высокие, но нарушения инструкций снижают надежность.
• В Automate заметно падение correctness (ниже 4) при сохранении средней релевантности — критический риск.🚨 Опасные профили:
• Категории с ориентацией на бизнес и безопасность (Create, Learn, Decide) демонстрируют риски вводящих в заблуждение рекомендаций.
• Технические категории (Fix, Automate, Optimize, Do) имеют риски нарушения корректности, что может привести к системным сбоям и потере данных/безопасности.
• Chat и Explore — риски искажения коммуникации и генерации бесполезных идей соответственно.🕳️ Структурные пробелы:
• Слабая устойчивость в задачах автоматизации и оптимизации процессов.
• Недостаток формализованной аргументации и пошаговости в Do и Fix.
• Отсутствие убедительного использования примеров и результатов проверки в Learn.🌊 Нестабильность уверенности:
• Значительная разбросанность Correctness и Instruction Following от 3–4 (Automate) до 8–9 (Chat, Decide), что указывает на нестабильность при переходе от когнитивных к техническим задачам.
III. Общий вывод
Категории для сложных интеллектуальных задач с высокой надежностью:
Chat, Decide, Explore. Здесь модель демонстрирует надежное понимание, корректность и структурированность выводов.Категории средней сложности с потенциалом использования при контроле:
Create, Learn. Здесь есть реальные недостатки в корректности и адекватности, требующие дополнительной валидации и доработки.Категории ограниченной применимости для экспериментального или пилотного использования:
Do, Fix, Optimize. Высокие риски ошибок, проблем с прозрачностью и неполной реализацией требований увеличивают вероятность плохих исходов без внешнего контроля.Категория, где использование модели не рекомендовано:
Automate — из-за критических ошибок, отсутствия полноты и низкого технического исполнения.Рекомендации для улучшения и внедрения:
- Автоматическая валидация и мониторинг исходов критичны в Do, Fix и Optimize для предотвращения ошибок и регрессий.
- В Create и Learn необходима экспертная проверка фактов и консистентности.
- Для Decisive задач и Explore возможна автономная эксплуатация с умеренным риском.
- Chat подходит для production как средство коммуникации с контролем за соблюдением границ фасилитации.В целом модель демонстрирует высокий уровень по категориям диалогового взаимодействия и принятия решений, средний уровень в генерации идей и обучения, а также сниженные показатели при задачах практического выполнения, исправления, оптимизации и автоматизации. Это указывает на сильные стороны в когнитивных и коммуникативных функциях при относительной слабости в технических, структурных и формализованных сценариях.